> 2003 Proceedings Contents [ISBN: 1-873699-93-X]
An Open Standard for Chemical Structure Representation - The IUPAC Chemical Identifier
Stephen E.
Stein, Stephen R. Heller, and Dmitrii
Tchekhovski
Physical and Chemical Properties Division,
NIST
Gaithersburg, MD 20899 USA
Emails: [email protected],
Abstract
IUPAC has long been involved in the development of systematic and standard procedures for naming chemical substances on the basis of their structure. The resulting rules of nomenclature, while covering almost all compounds, were designed for text-based media. IUPAC is now developing a means of representing chemical substances in a format more suitable for digital processing, involving the computer processing of chemical structural information (connection tables). This is being implemented in the IUPAC Chemical Identifier project, details of which will be discussed in this presentation.
Background
In March 2000 IUPAC convened a meeting in Washington DC to look into the matter of chemical structure representation (1). The IUPAC Strategy Roundtable meeting was called “Representations of Molecular Structure: Nomenclature and its Alternatives”. It brought together 41 participants from 10 countries including experts in organic, inorganic, biochemical, and macromolecular nomenclature; users of nomenclature in academia, industry, the patent, international trade, health and safety communities; journal editors and publishers; database providers; and software vendors.
Over the past decade with the ever-increasing reliance on computer processing by chemists, it became evident to many within IUPAC that this organization should find better ways of handling nomenclature was done in the past. In particular it was felt by the authors that while IUPAC had stressed conventional chemical names/nomenclature in the 20th century, continued progress into the 21st century required new, computer-driven approaches to the problem of chemical identification.
At the meeting in March 2000 the authors presented a proposal to IUPAC, which extended one developed by one of the authors (SRH) in the fall of 1999. The initial proposal from November 1999 was widely circulated with the chemical information and chemical structure representation community via e-mail. The proposal presented at the March 2000 meeting was incorporated considerable improvements from this feedback from chemists in the USA, Europe, and Asia.
At the end of the March 2000 meeting Bill Town (2) proposed that the new program be called IUPAC Chemical Identifier Project (IChIP)
The aim of the IUPAC Chemical Identifier Project (IChIP) is to establish a unique label, the IUPAC Chemical Identifier (IChI), which would be a non-proprietary identifier for chemical substances that could be used in printed and electronic data sources thus enabling easier linking of diverse data compilations and unambiguous identification of chemical substances.
IChI is not a registry system. It does not depend on the existence of a database of unique substance records to establish the next available sequence number for any new chemical substance being assigned an IChI. It will be based on a set of IUPAC structure conventions, and rules for normalization and canonicalization (3) of an input structure representation to establish the unique label. It will thus enable an automatic conversion of a graphical representation of a chemical substance into the unique IChI label which can
be created independently of any organization anywhere in the world and which could be built into any chemical structure drawing program and created from any existing collection of chemical structures.
As a result of the meeting and the recommendations in the report (1) the following was approved by IUPAC In April 2000 (4,5):
1. An ad hoc Committee on Chemical Identity and Nomenclature Systems (CCINS) has been established, with Dr. Alan D. McNaught (6) as Chairman. The CCINS is responsible for developing systems for conventional and computer-based chemical nomenclature; cooperating with the four current IUPAC nomenclature Commissions; coordinating interdisciplinary activities in the nomenclature field; and recommending to the Bureau long-range strategy on chemical nomenclature. It is expected that this body will provide the long-term central planning, management and coordination of chemical nomenclature that would otherwise be lost when the Commissions are discontinued at the end of 2001.
2. A feasibility study of the Chemical Identifier project, to be managed by the CCINS, has been initiated. A "chemical identifier" is intended to be a meaningful alphanumeric text string that can uniquely identify a chemical compound and facilitate its handling in computer databases. This code would be the equivalent of an IUPAC systematic name but would be designed to be information about the specific substance in question. Since there are several issues to be resolved, the participants in the Nomenclature Round Table recommended that the feasibility of the project and resolution of these issues be carried out as soon as possible by representatives of a wide range of interested parties. Drs. Stephen R. Heller and Steve Stein (NIST) were asked to recommend a list of individuals and groups that should be consulted initially and to propose a framework for addressing the issues.
3. IUPAC has agreed to play a lead role in representing the international chemistry communities in the development of Chemical Markup Language (CML) (7), which is an extension of the more general XML (Extended Markup Language) with special ability to handle chemical information. XML is a new standard being adopted by web publishers worldwide. It is expected to replace the current standard HTML over the next few years.
In August 2000 a meeting was held in Cambridge UK to discuss a number of technical issues before actual work on the project began. A detailed proposal was then prepared and IUAPC requested the assistance from NIST to provide the bulk of the technical support for the project. In December 2000 the project was approved by IUPAC and officially started on January 1, 2001 (3). Initial reports on the project were presented at the IUPAC 38th Congress - invited talk on the IUPAC IChI Project - July, 2001,
at the ACS National Meeting in Chicago, Illinois-- August, 2001, the CAS/IUPAC Conference on Chemical Identifiers and XML for Chemistry, July, 2002 , and at the US Government Conference on Chemical Databases - July, 2003 (8). In addition a number of articles have appeared in chemistry and science publications regarding the IChI project (9-12).
Introduction:
The most widely-used, and perhaps best understood object under discussion in chemistry is the chemical compound. Of course, we define chemical compounds by their chemical structure, as typically shown in 2D diagrams or stored in computers as ‘connection tables’.
Pronounceable names have been developed for oral and written communication, though derivation of a name from a structure can require highly complex rules known only to experts. ‘Understanding’ these names requires reversing the naming process to derive the original structure. They are very indirect and inefficient means of identifying chemicals.
In the current digital age, where compounds are represented digitally, the need for effective identifiers is no less important. Freed from the restriction of ‘pronounceability’, chemical identifiers can be tied more directly to structures. In fact, they can be derived directly from structure by algorithm such that any structure that can be drawn can be ‘identified’.
The IChI project aims to develop such a set of algorithms to serve as the unique identifier for each compound, its digital signature. Since a series of characters is the method of storage and transmission of information, such a string, derived from a structure, is the output format.

While the most fundamental description of the identity of a compound is its
structure, this requires a picture, which is not usable for speech and often
inconvenient for text. The use of pronounceable names is very efficient for
common substances, which
Figure 1 – Problems with existing chemical identifiers
While the most fundamental description of the identity of a compound is its structure, this requires a picture, which is not usable for speech and often inconvenient for text. The use of pronounceable names is very efficient for common substances, which often acquire a ‘trivial’ name, but can be cumbersome or impossible for complex compounds.
As one can see from Figure 1, it could be argued that the principal problems with chemical identifiers is that there are too many of them. From a computer standard point all are defective. Figure 2 indicates what is needed to have a good identifier.

Figure 2: What kind of Identifier is needed?
The basic requirements, as noted below in Figures 3 and 4, are that different compounds need to have different identifiers and the same compound must give the same identifier.

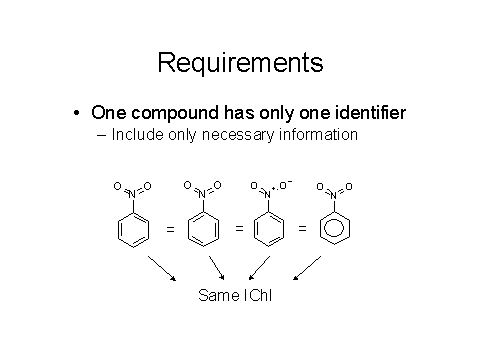
Figures 3 & 4: Requirements for a good chemical identifier
IChI Beta Version
Capabilities

Figure 5 – Initial Capabilities of the IChI Algorithm
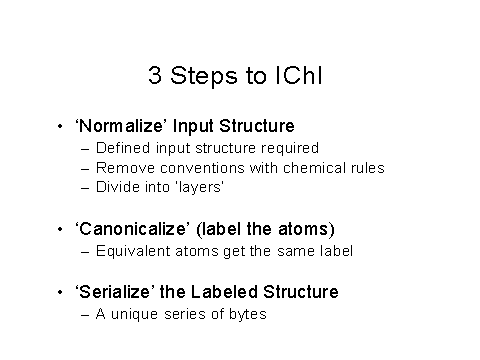
Figure 6 – First three steps to create an IChI

Figure 7 – IChI simplifications

Figure 8 – Ignoring the electron density of a chemical structure
Figures 6,7, and 8 show the 3 steps to obtain an IChI, including normalization and the simplifications used, including ignoring electron density.
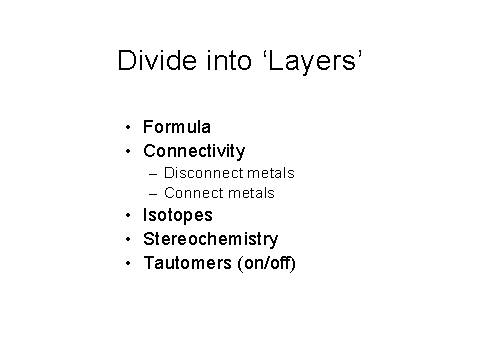
Figure 9 – The initial layers used in the IChI
algorithm
Figure 9 shows the highly flexible layered approach being taken to be able to represent all aspects of a chemical. The layered approach is logical (separate the variables), easily understandable, has no significant computational ‘cost’. It is also very flexible for chemists – represent known level of information. It is very easy to add more layers as needed to cover polymers, Markush structures, alloys, clusters, phase diagrams, conformation, coordination, and so on.
Figures 10-11 below show how metals and non-metals are handled in the layer approached being used:
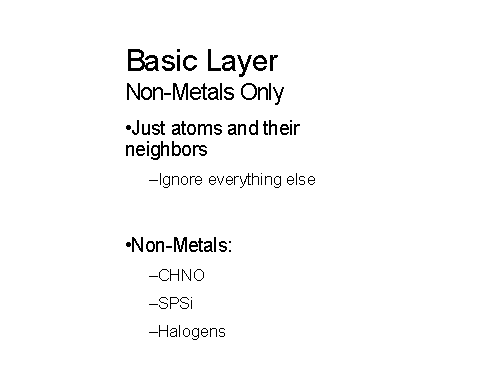
Figure 10 – The IChI basic non-metal layer
Metals Layer
Bonds to ‘Metals’
•
All bonds to metals
–
Ignore bond type
•
Empty if no bonds to
metals
•
Use when bonding is
known and significant
Figure 11 – The IChI metal layer
In the area of stereochemistry the IChI algorithm currently handles double bonds and tetrahedral (sp3) geometry are shown in Figure 12.

Figure 12 –
Stereochemistry in IChI
Tautomers also handled by IChI, but will not be discussed in this report.
IChI Output
IChI Output
9 possible fields
•
Basic – non-metal ##
–
Metal ##
–
Isotopic ##
•Stereo ##
–
Stereo ##
•
Tautomer – non-metal ##
–
Metal ##
–
Isotopic ##
•Stereo ##
–
Stereo ##
•
Electronic ##
Figure 13 – Nine possible
IChI output fields
The current draft IChI output fields are shown in Figure 13, with an actual example of benzene shown below in Figure 14.

Figure 14 –
Example of the draft IChI output for Benzene
Algorithm Testing
The IChI algorithm has been extensively tested. Over 100 copies of the best test version have been disseminated in the past 18 months and the feedback, while generally sparse, has been useful. No flaws have yet turned up, even when very complex structures, such as shown in Figures 15 and 16 have been tested (13). The speed of the algorithm is excellent, with typical structures taking less than 2 milliseconds on a medium speed (1 GHz) PC.
Figure 15 – Example of a large complex molecule handled by the IChI algorithm
Figure 16 – Example of an
extremely large and symmetrically complex molecule handled by the IChI
algorithm
Summary
In a short period of some 3 ½ years, the IUPAC IChI project has gone from conception to testing a well developed implemented public domain algorithm for standard chemical structure representation. Much technical work remains to be done. Even more important is the need for acceptance of the algorithm. To date the response from database organizations and software companies that produce structure drawing programs has been most encouraging. An initial working version covering the basic organic chemical structures for public use is expected by the end of 2003. Work on coverage of additional classes of chemicals continues and a further progress report will be forthcoming in the next 12-18 months.
References:
1. http://www.iupac.org/organ/ad_hoc_cmt/nomenclature/NRT_Report.html
2. Bill Town, Kilmorie Consulting, 24A Elsinore Road, London SE23 2SL,
UK, Email: [email protected]
3. John M. Barnard, “Structure Representation”, Chapter in Encyclopedia of
Computational Chemistry, 5 Volume Set
Paul von Ragué Schleyer
(Editor-in-Chief)
ISBN: 0-471-96588-X, John Wiley,1999.
4. The project was officially announced in Chemistry International, Volume 23, Number 3, May 2001: http://www.iupac.org/publications/ci/2001/may/project_2000-025-1-050.html
5. IUPAC IChI project information is available at: http://www.iupac.org/projects/2000/2000-025-1-800.html
6. Alan McNaught, Royal Society of Chemistry, Thomas Graham House, Science Park, Milton Road, Cambridge CB4 0WF, UK, Email:[email protected]
7.P. Murray-Rust and H. S. Rzepa, chapter in "Handbook of Chemoinformatics. Part 2. Advanced Topics.", ed. J. Gasteiger and T. Engel, 2003, in press.
8. The slides from these two presentations are available at: http://www.hellers.com/steve/pub-talks/
9. “What’s in a Name” ChemWeb – The Alchemist, March 21, 2002. Available at: http://www.chemweb.com/alchem/articles/1015947151360.html
10. “That IChI feeling”, ChemWeb – The
Alchemist, April 24, 2002. Available
at: http://www.chemweb.com/alchem/articles/1015947904091.html
11. David Adam , “Chemists Synthesize a Single Naming System” Nature![]() 417, 369 (23 May 2002)
417, 369 (23 May 2002)
12. Michael
Freemantle , “Unique Label for Compounds”, C&E News article: December 2, 2002. Also available on the web
at: http://pubs.acs.org/cen/today/nov26.html
13. Mathon, R. “Sample Graphs for Isomorphism Testing” Congressus Numerantium V21, pp. 499-517, 1978